=====================================================
Kalyan Spark + Phoenix + Flume + Play Project
=====================================================
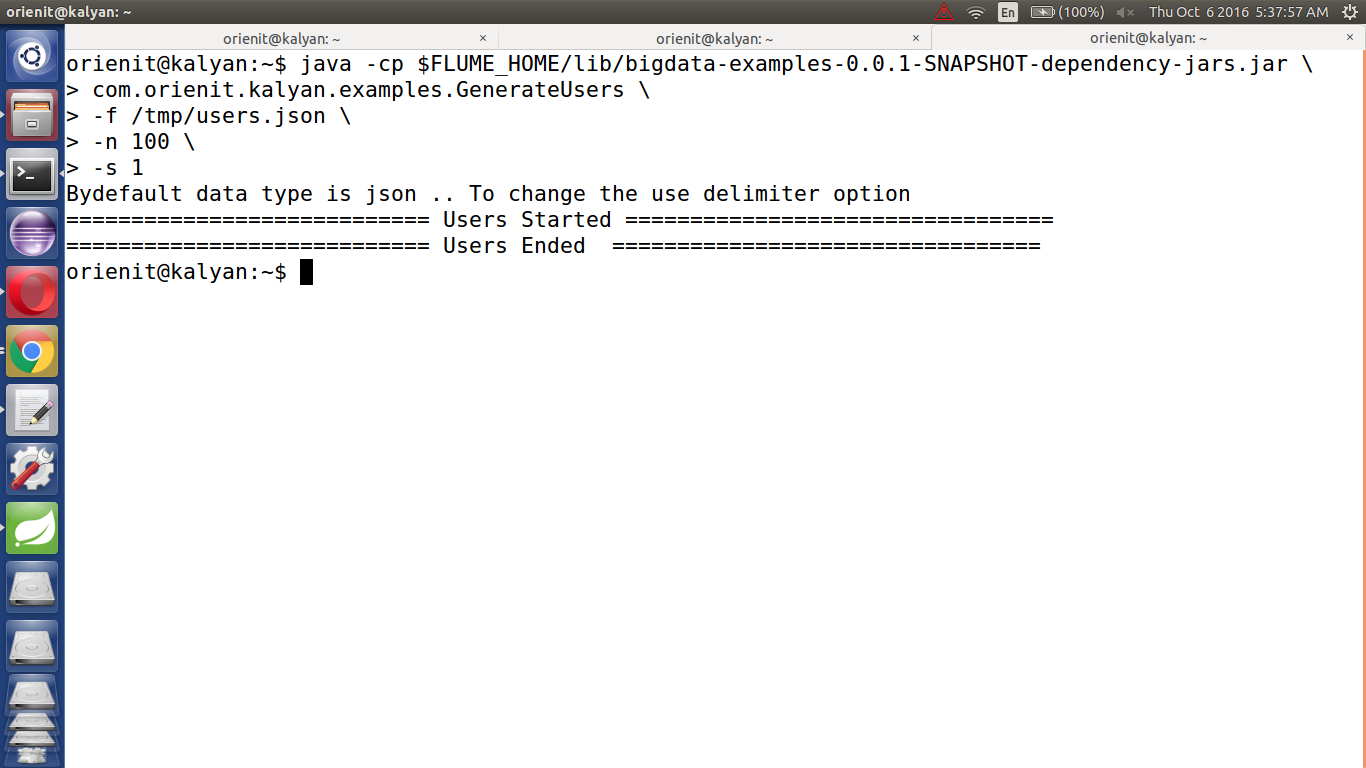
1. Generate Sample Users
2. Generate Sample Product Logs
3. Using the `Flume` transfer the `product.log` file changes to `Phoenix`
4. Use `Spark Streaming` to listen `Flume` data

7. Execute below command
%sql
select * from prouctlog

8. Execute below command
%sql
select userid, count(*) as cnt from prouctlog group by userid

9. Check the below graphs





Kalyan Spark + Phoenix + Flume + Play Project
=====================================================
1. Generate Sample Users
2. Generate Sample Product Logs
3. Using the `Flume` transfer the `product.log` file changes to `Phoenix`
4. Use `Spark Streaming` to listen `Flume` data
5. Save the streaming data into `Phoenix` for analytics
6. Give Real-Time analysis on `Phoenix` data using UI tools
7. You can still add your own features
8. Visualize data in UI
======================================================
Execute the below operations
======================================================
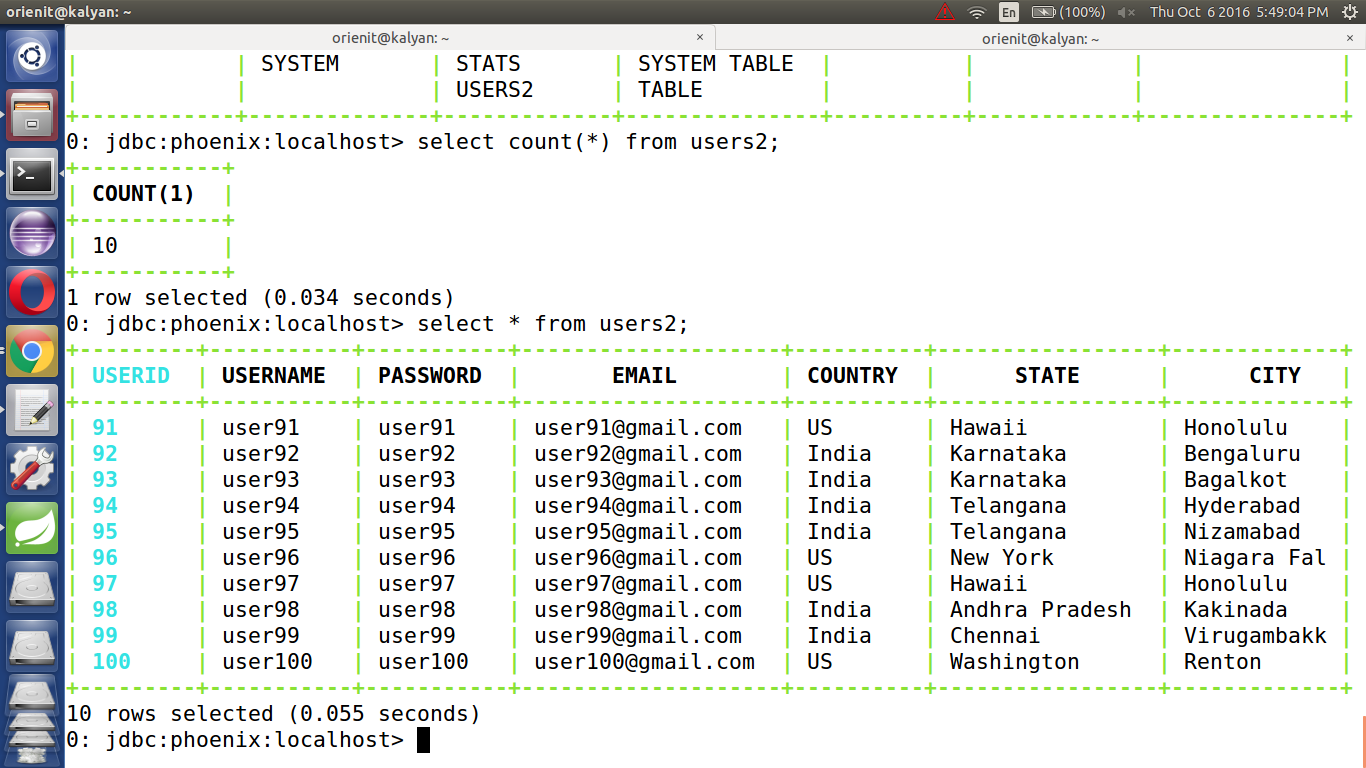
1. Execute the below `Phoenix Operations`
Start the Hadoop , Hbase & Phoenix
DROP TABLE users;
CREATE TABLE users("userid" bigint PRIMARY KEY, "username" varchar, "password" varchar, "email" varchar, "country" varchar, "state" varchar, "city" varchar, "dt" varchar);
DROP TABLE productlog;
CREATE TABLE IF NOT EXISTS productlog("userid" bigint not null, "username" varchar, "email" varchar, "product" varchar not null, "transaction" varchar, "country" varchar, "state" varchar, "city" varchar, "dt" varchar not null CONSTRAINT pk PRIMARY KEY ("userid", "product", "dt"));
2. Generate Sample Users by running `GenerateUsers.scala` code

3. Execute the below `Flume Operations`
Create `kalyan-spark-project` folder in `$FLUME_HOME` folder
Copy `exec-avro.conf` file into `$FLUME_HOME/kalyan-spark-project` folder
Execute below command to start flume agent
$FLUME_HOME/bin/flume-ng agent -n agent --conf $FLUME_HOME/conf -f $FLUME_HOME/kalyan-spark-project/exec-avro.conf -Dflume.root.logger=DEBUG,console
4. Generate Sample Logs by running `GenerateProductLog.scala`

5. Execute the below `Spark Operations`
Stream Sample Logs From Flume Sink using `Spark Streaming` by running `KalyanSparkFlumeStreaming.scala` and pass the below arguments
2 localhost 1234 false

Stream Sample Logs From Kafka Producer using `Spark Streaming` by running `KalyanSparkKafkaStreaming.scala` and pass the below arguments
2 topic1,topic2 localhost:9092 false

6. Use Zeppelin for UI
=============================================================
Kalyan Spark + Phoenix + Flume + Play Project : Visualization
=============================================================
1. Open new Terminal
2. Change the directory using below command
cd /home/orienit/spark/workspace/kalyan-spark-streaming-phoenix-project
3. Run the Project using below command
activator run

4. Open the browser with below link : Home Page
http://localhost:9000/

5. Open the browser with below link : Users Page
http://localhost:9000/kalyan/users

6. Open the browser with below link : Different Graphs
http://localhost:9000/kalyan/home

7. Open the browser with below link : Products Page 1
http://localhost:9000/kalyan/graphs/products

8. Open the browser with below link : Products Page 2
http://localhost:9000/kalyan/graphs/products

============================================================
Kalyan Spark + Phoenix + Flume + Play Project : Zeppelin Visualization
============================================================
1. Open new Terminal
2. Run the Zeppelin Project using below command
zeppelin-daemon.sh start
3. Open the browser using below link
http://localhost:8080/
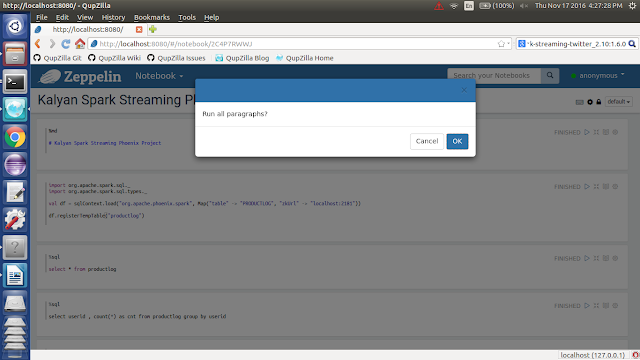
4. Create a new Notebook with name is `Kalyan Spark Streaming Phoenix Project`
5. Follow the below screenshot
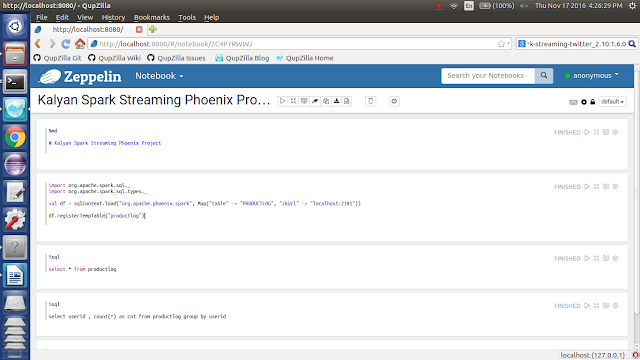
6. Run the paragraphs
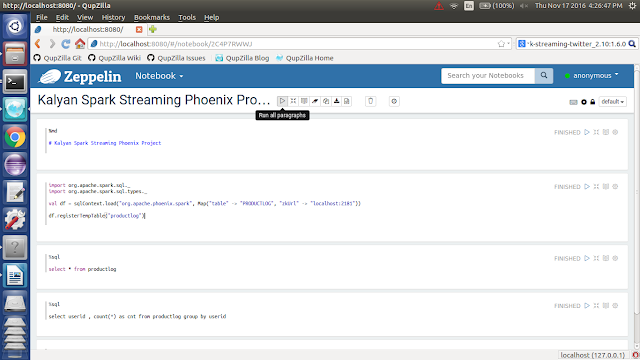
6. Give Real-Time analysis on `Phoenix` data using UI tools
7. You can still add your own features
8. Visualize data in UI
======================================================
Execute the below operations
======================================================
1. Execute the below `Phoenix Operations`
Start the Hadoop , Hbase & Phoenix
DROP TABLE users;
CREATE TABLE users("userid" bigint PRIMARY KEY, "username" varchar, "password" varchar, "email" varchar, "country" varchar, "state" varchar, "city" varchar, "dt" varchar);
DROP TABLE productlog;
CREATE TABLE IF NOT EXISTS productlog("userid" bigint not null, "username" varchar, "email" varchar, "product" varchar not null, "transaction" varchar, "country" varchar, "state" varchar, "city" varchar, "dt" varchar not null CONSTRAINT pk PRIMARY KEY ("userid", "product", "dt"));
2. Generate Sample Users by running `GenerateUsers.scala` code
3. Execute the below `Flume Operations`
Create `kalyan-spark-project` folder in `$FLUME_HOME` folder
Copy `exec-avro.conf` file into `$FLUME_HOME/kalyan-spark-project` folder
Execute below command to start flume agent
$FLUME_HOME/bin/flume-ng agent -n agent --conf $FLUME_HOME/conf -f $FLUME_HOME/kalyan-spark-project/exec-avro.conf -Dflume.root.logger=DEBUG,console
4. Generate Sample Logs by running `GenerateProductLog.scala`
5. Execute the below `Spark Operations`
Stream Sample Logs From Flume Sink using `Spark Streaming` by running `KalyanSparkFlumeStreaming.scala` and pass the below arguments
2 localhost 1234 false
Stream Sample Logs From Kafka Producer using `Spark Streaming` by running `KalyanSparkKafkaStreaming.scala` and pass the below arguments
2 topic1,topic2 localhost:9092 false
6. Use Zeppelin for UI
=============================================================
Kalyan Spark + Phoenix + Flume + Play Project : Visualization
=============================================================
1. Open new Terminal
2. Change the directory using below command
cd /home/orienit/spark/workspace/kalyan-spark-streaming-phoenix-project
3. Run the Project using below command
activator run
4. Open the browser with below link : Home Page
http://localhost:9000/
5. Open the browser with below link : Users Page
http://localhost:9000/kalyan/users
6. Open the browser with below link : Different Graphs
http://localhost:9000/kalyan/home
7. Open the browser with below link : Products Page 1
http://localhost:9000/kalyan/graphs/products
8. Open the browser with below link : Products Page 2
http://localhost:9000/kalyan/graphs/products
============================================================
Kalyan Spark + Phoenix + Flume + Play Project : Zeppelin Visualization
============================================================
1. Open new Terminal
2. Run the Zeppelin Project using below command
zeppelin-daemon.sh start
3. Open the browser using below link
http://localhost:8080/
4. Create a new Notebook with name is `Kalyan Spark Streaming Phoenix Project`
5. Follow the below screenshot
6. Run the paragraphs
7. Execute below command
%sql
select * from prouctlog
8. Execute below command
%sql
select userid, count(*) as cnt from prouctlog group by userid
9. Check the below graphs