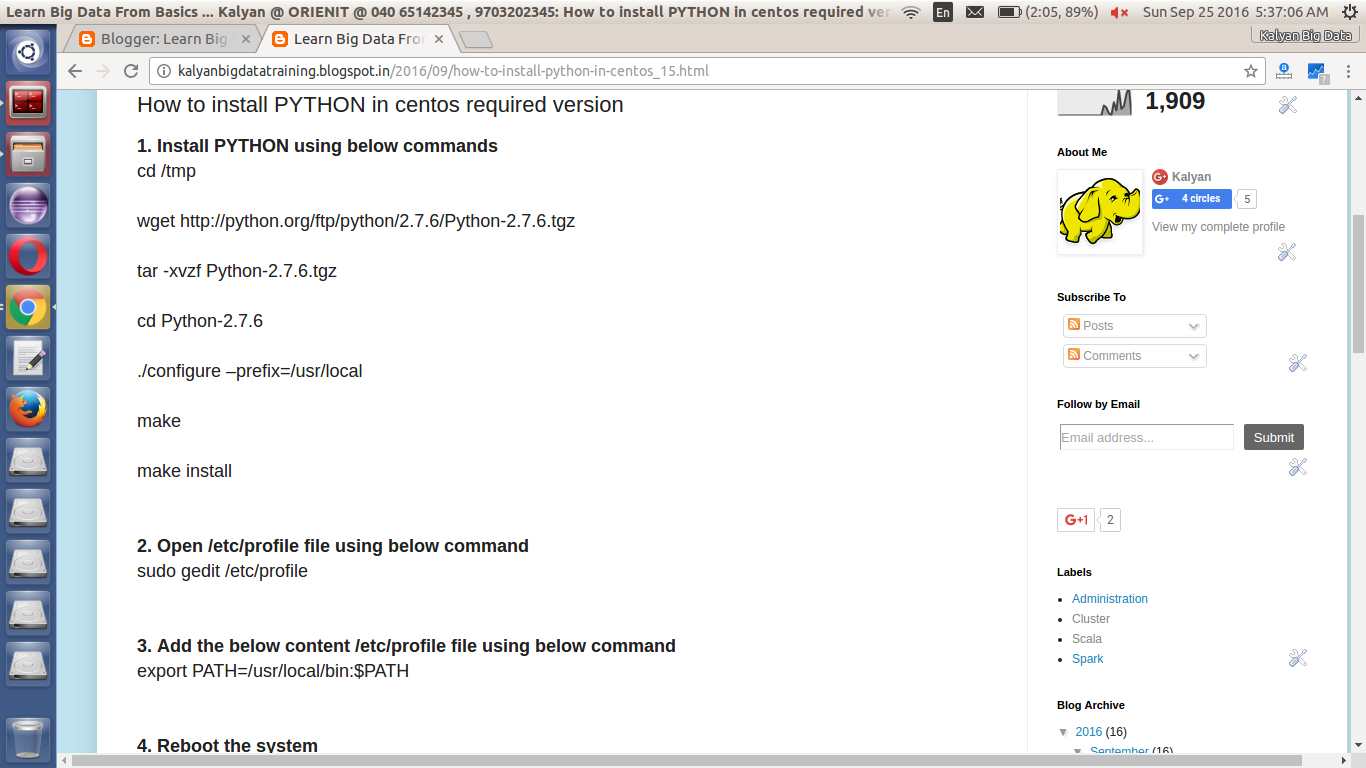
Sizing your Hadoop cluster
Hadoop's performance depends on multiple factors based on well-configured software layers and well-dimensioned hardware resources that utilize its CPU, Memory, hard drive (storage I/O) and network bandwidth efficiently.
Planning the Hadoop cluster remains a complex task that requires minimum knowledge of the Hadoop architecture and may be out the scope of this book. This is what we are trying to make clearer in this section by providing explanations and formulas in order to help you to best estimate your needs. We will introduce a basic guideline that will help you to make your decision while sizing your cluster and answer some How to plan questions about cluster's needs such as the following:
- How to plan my storage?
- How to plan my CPU?
- How to plan my memory?
- How to plan the network bandwidth?
While sizing your Hadoop cluster, you should also consider the data volume that the final users will process on the cluster. The answer to this question will lead you to determine how many machines (nodes) you need in your cluster to process the input data efficiently and determine the disk/memory capacity of each one.
Hadoop is a Master/Slave architecture and needs a lot of memory and CPU bound. It has two main components:
- JobTracker: This is the critical component in this architecture and monitors jobs that are running on the cluster
- TaskTracker: This runs tasks on each node of the cluster
To work efficiently, HDFS must have high throughput hard drives with an underlying filesystem that supports the HDFS read and write pattern (large block). This pattern defines one big read (or write) at a time with a block size of 64 MB, 128 MB, up to 256 MB. Also, the network layer should be fast enough to cope with intermediate data transfer and block.
HDFS is itself based on a Master/Slave architecture with two main components: the NameNode / Secondary NameNode and DataNode components. These are critical components and need a lot of memory to store the file's meta information such as attributes and file localization, directory structure, names, and to process data. The NameNode component ensures that data blocks are properly replicated in the cluster. The second component, the DataNode component, manages the state of an HDFS node and interacts with its data blocks. It requires a lot of I/O for processing and data transfer.
Typically, the MapReduce layer has two main prerequisites: input datasets must be large enough to fill a data block and split in smaller and independent data chunks (for example, a 10 GB text file can be split into 40,960 blocks of 256 MB each, and each line of text in any data block can be processed independently). The second prerequisite is that it should consider the data locality, which means that the MapReduce code is moved where the data lies, not the opposite (it is more efficient to move a few megabytes of code to be close to the data to be processed, than moving many data blocks over the network or the disk). This involves having a distributed storage system that exposes data locality and allows the execution of code on any storage node.
Concerning the network bandwidth, it is used at two instances: during the replication process and following a file write, and during the balancing of the replication factor when a node fails.
The most common practice to size a Hadoop cluster is sizing the cluster based on the amount of storage required. The more data into the system, the more will be the machines required. Each time you add a new node to the cluster, you get more computing resources in addition to the new storage capacity.
Let's consider an example cluster growth plan based on storage and learn how to determine the storage needed, the amount of memory, and the number of DataNodes in the cluster.
Daily data input
|
100 GB
|
Storage space used by daily data input = daily data input * replication factor = 300 GB
|
HDFS replication factor
|
3
| |
Monthly growth
|
5%
|
Monthly volume = (300 * 30) + 5% = 9450 GB
After one year = 9450 * (1 + 0.05)^12 = 16971 GB
|
Intermediate MapReduce data
|
25%
|
Dedicated space = HDD size * (1 - Non HDFS reserved space per disk / 100 + Intermediate MapReduce data / 100)
= 4 * (1 - (0.25 + 0.30)) = 1.8 TB (which is the node capacity)
|
Non HDFS reserved space per disk
|
30%
| |
Size of a hard drive disk
|
4 TB
| |
Number of DataNodes needed to process:
Whole first month data = 9.450 / 1800 ~= 6 nodes
The 12th month data = 16.971/ 1800 ~= 10 nodes
Whole year data = 157.938 / 1800 ~= 88 nodes
| ||
Do not use RAID array disks on a DataNode. HDFS provides its own replication mechanism. It is also important to note that for every disk, 30 percent of its capacity should be reserved to non-HDFS use.
It is easy to determine the memory needed for both NameNode and Secondary NameNode. The memory needed by NameNode to manage the HDFS cluster metadata in memory and the memory needed for the OS must be added together. Typically, the memory needed by Secondary NameNode should be identical to NameNode. Then you can apply the following formulas to determine the memory amount:
NameNode memory
|
2 GB - 4 GB
|
Memory amount = HDFS cluster management memory + NameNode memory + OS memory
|
Secondary NameNode memory
|
2 GB - 4 GB
| |
OS memory
|
4 GB - 8 GB
| |
HDFS memory
|
2 GB - 8 GB
| |
At least NameNode (Secondary NameNode) memory = 2 + 2 + 4 = 8 GB
| ||
It is also easy to determine the DataNode memory amount. But this time, the memory amount depends on the physical CPU's core number installed on each DataNode.
DataNode process memory
|
4 GB - 8 GB
|
Memory amount = Memory per CPU core * number of CPU's core + DataNode process memory + DataNode TaskTracker memory + OS memory
|
DataNode TaskTracker memory
|
4 GB - 8 GB
| |
OS memory
|
4 GB - 8 GB
| |
CPU's core number
|
4+
| |
Memory per CPU core
|
4 GB - 8 GB
| |
At least DataNode memory = 4*4 + 4 + 4 + 4 = 28 GB
| ||
Regarding how to determine the CPU and the network bandwidth, we suggest using the now-a-days multicore CPUs with at least four physical cores per CPU. The more physical CPU's cores you have, the more you will be able to enhance your job's performance (according to all rules discussed to avoid underutilization or overutilization). For the network switches, we recommend to use equipment having a high throughput (such as 10 GB) Ethernet intra rack with N x 10 GB Ethernet inter rack.
Configuring your cluster correctly
To run Hadoop and get a maximum performance, it needs to be configured correctly. But the question is how to do that. Well, based on our experiences, we can say that there is not one single answer to this question. The experiences gave us a clear indication that the Hadoop framework should be adapted for the cluster it is running on and sometimes also to the job.
In order to configure your cluster correctly, we recommend running a Hadoop job(s) the first time with its default configuration to get a baseline. Then, you will check the resource's weakness (if it exists) by analyzing the job history logfiles and report the results (measured time it took to run the jobs). After that, iteratively, you will tune your Hadoop configuration and re-run the job until you get the configuration that fits your business needs.
The number of mappers and reducer tasks that a job should use is important. Picking the right amount of tasks for a job can have a huge impact on Hadoop's performance.
The number of reducer tasks should be less than the number of mapper tasks. Google reports one reducer for 20 mappers; the others give different guidelines. This is because mapper tasks often process a lot of data, and the result of those tasks are passed to the reducer tasks. Often, a reducer task is just an aggregate function that processes a minor portion of the data compared to the mapper tasks. Also, the correct number of reducers must also be considered.
The number of mappers and reducers is related to the number of physical cores on the DataNode, which determines the maximum number of jobs that can run in parallel on DataNode.
In a Hadoop cluster, master nodes typically consist of machines where one machine is designed as a NameNode, and another as a JobTracker, while all other machines in the cluster are slave nodes that act as DataNodes and TaskTrackers. When starting the cluster, you begin starting the HDFS daemons on the master node and DataNode daemons on all data nodes machines. Then, you start the MapReduce daemons: JobTracker on the master node and the TaskTracker daemons on all slave nodes. The following diagram shows the Hadoop daemon's pseudo formula:

When configuring your cluster, you need to consider the CPU cores and memory resources that need to be allocated to these daemons. In a huge data context, it is recommended to reserve 2 CPU cores on each DataNode for the HDFS and MapReduce daemons. While in a small and medium data context, you can reserve only one CPU core on each DataNode.
Once you have determined the maximum mapper's slot numbers, you need to determine the reducer's maximum slot numbers. Based on our experience, there is a distribution between the Map and Reduce tasks on DataNodes that give good performance result to define the reducer's slot numbers the same as the mapper's slot numbers or at least equal to two-third mapper slots.
Let's learn to correctly configure the number of mappers and reducers and assume the following cluster examples:
Cluster machine
|
Nb
|
Medium data size
|
Large data size
|
DataNode CPU cores
|
8
|
Reserve 1 CPU core
|
Reserve 2 CPU cores
|
DataNode TaskTracker daemon
|
1
|
1
|
1
|
DataNode HDFS daemon
|
1
|
1
|
1
|
Data block size
|
128 MB
|
256 MB
| |
DataNode CPU % utilization
|
95% to 120%
|
95% to 150%
| |
Cluster nodes
|
20
|
40
| |
Replication factor
|
2
|
3
|
We want to use the CPU resources at least 95 percent, and due to Hyper-Threading, one CPU core might process more than one job at a time, so we can set the Hyper-Threading factor range between 120 percent and 170 percent.
Maximum mapper's slot numbers on
one node in a large data context |
= number of physical cores - reserved core * (0.95 -> 1.5)
Reserved core = 1 for TaskTracker + 1 for HDFS
|
Let's say the CPU on the node will use up to 120% (with Hyper-Threading)
Maximum number of mapper slots = (8 - 2) * 1.2 = 7.2 rounded down to 7
| |
Let's apply the 2/3 mappers / reducers technique:
Maximum number of reducers slots = 7 * 2/3 = 5
| |
Let's define the number of slots for the cluster:
Mapper's slots: = 7 * 40 = 280
Reducer's slots: = 5 * 40 = 200
| |
The block size is also used to enhance performance. The default Hadoop configuration uses 64 MB blocks, while we suggest using 128 MB in your configuration for a medium data context as well and 256 MB for a very large data context. This means that a mapper task can process one data block (for example, 128 MB) by only opening one block. In the default Hadoop configuration (set to 2 by default), two mapper tasks are needed to process the same amount of data. This may be considered as a drawback because initializing one more mapper task and opening one more file takes more time.
Summary
In this article, we learned about sizing and configuring the Hadoop cluster for optimizing it for MapReduce.
Resources for Article:
- Hadoop Tech Page
- Hadoop and HDInsight in a Heartbeat
- Securing the Hadoop Ecosystem
- Advanced Hadoop MapReduce Administration